FAQ
FAQ
- Can you introduce mysql2hive in detail, such as how to calculate the parallelism, and some of its overall performance.
mysql2hive has a strategy for automatically calculating the parallelism, which is related to the number of slaves. At the same time, there will be an upper limit to prevent the mysql load from causing relatively large pressure.
- The default parallelism of input is related to the size and distribution of data, determined by the createInputSplits function, and the maximum is 100.
- The default parallelism of output is related to the number and size of the data volume. The specific rules are: max (recommended parallelism of input, min (100 million/32 parallelism, 100G/32 parallelism)), and the maximum is 100.
In terms of performance, it can currently stably support tens of billions of rows, and for tens of millions of tables, the import can be completed in minutes.
- How does the automatic parallelism measure work? At present, we all have a fixed parallelism, and the development and operation and maintenance costs are relatively high.
According to the number and size of the input data, set an automatic calculation algorithm. Suppose our data has 100 million pieces or 100G, how many pieces we assign a parallelism to it, and how much data volume we assign it a parallelism. At the same time, we also need to consider the upper limit of the parallelism that each data source can bear. Prevent the high load of input and output data sources caused by too much parallelism.
Reference document: Parallelism Computing
- Does BitSail support ClickHouse Writer?
At present, BitSail already supports the reading of ClickHouse, and will also support the writing of ClickHouse in the future. After BitSail is open-sourced, we have completed some common Connectors. But from the perspective of the entire Connector ecology, it is far from enough, because the Connectors and scenarios used by each company are different. We hope to call on everyone to participate in the contribution and improve the entire Connector ecology together. At the same time, we have also started the contribution Incentive activities to encourage everyone to participate and improve.
- With so many scenarios, how should we identify dirty data?
The current strategy is as follows: data that involves reading and writing of data sources is not considered dirty data. For example, data writing fails due to network jitters. If it is considered dirty data, it will eventually lead to data loss.
The dirty data mentioned here focuses more on scenarios such as data parsing, data conversion failure, and data overflow during data transmission. Such data will be considered dirty data, but normal reading and writing will not be judged as dirty data.
- What are the application scenarios of BitSail?
BitSail is a data engine that provides high-performance, high-reliability data synchronization between massive data, and provides data processing capabilities that integrate stream batching and lake warehouse integration. At the architectural level, it is a data integration engine that supports distributed and cloud native.
During the data construction process, the following scenarios are more suitable for using BitSail:
- There are obvious data integration needs, but there are currently no clear solutions;
- Encountered problems in maturity, stability, or performance, or encountered problems in technical architecture, such as wanting to support distributed, cloud-native architecture; wanting to support the ability to integrate streaming and batching; incremental data synchronization based on CDC, etc.
BitSail has deep experience in the above scenarios, which are also the scenarios that BitSail will cover at present or in the future.
- On what levels will the advantages of BitSail be reflected?
The core competitiveness of BitSail is mainly reflected in the following dimensions:
- Product maturity: BitSail has withstood the production environment verification of many business lines of Byte, and has made a lot of optimizations in performance and reliability, which is more guaranteed in terms of maturity;
- Completeness of the architecture: The architecture supports stream-batch integration and lake-warehouse integration, which is perfectly compatible with the Hadoop ecology and is relatively flexible in the use of resources.
- Richness of basic functions: The development of data integration has reached the deep water area at this stage. We need not only to be usable, but also to be easy to use. At this level, BitSail has accumulated rich experience, such as dealing with dirty data collection, type conversion, parallelism calculation, etc. These are some problems that are often faced in the field of data integration.
- Does BitSail have a web interface? Is there a getting started operation video?
There is currently no product entry. BitSail aims to provide users with a common data integration engine to achieve data synchronization between different data sources. The future plan is to connect with different development platforms and scheduling platforms.
There will be an introductory operation video later. Each sharing will also have video retention. You can make some reference, we will also make up some user introductory videos on GitHub.
- Does BitSail support real-time collection of logs in log files on the server?
It is not supported at present. If necessary, you can raise an issue on GitHub. We will discuss the feasibility and demand with the developers in the community and launch this function together.
- Will the BitSail plan support Spark?
There is currently no plan to support spark. BitSail is currently working on a multi-engine architecture, but it does not mean that it will support different computing engines, such as Flink and Spark. The goal of BitSail is to shield the engine from users. Users do not need to perceive the existence of the underlying engine, but only need to feel the ability of BitSail data synchronization. What BitSail needs to do is optimize our performance and improve our operating efficiency for data integration scenarios.
- Is there a roadmap for K8s Runtime?
At present, we are working on the implementation and support of K8s Runtime.
- Does it support the synchronization of upstream table structure changes to downstream?
It is supported at the framework level, but the specific support is subject to the implementation of the specific Connector.
- The current flink version supports 1.11. Is there a version that supports 1.13?
At present, we have opened the corresponding issue on GitHub to start the 1.11 upgrade process. Next, we will start to do this, and everyone is welcome to participate in this process together.
- Is Kafka to Hive connector available at present?
Yes, we have made certain optimizations from Kafka to Hive, and developers can directly get started with BitSail to experience this process.
- Can Connector support multiple versions of the same type of data source?
It can be supported. Including kafka, this will actually happen. Therefore, we implement this dynamic loading to avoid internal conflicts in different versions of the same Connector.
- How does BitSail manage and monitor these data integration jobs? Is it in the form of command line?
Yes, currently it is through the command line.
- Does BitSail support data conversion? Does it support branch judgment to write to different targets?
Transform is not yet supported, and there are plans to build it with the community in the future.
- What are the requirements to become a BitSail Contributor?
Submit a Commit to become a BitSail Contributor. Regarding the nomination of Committers, we hope to evaluate the contribution of a Contributor from different dimensions to nominate Committers, including document contributions, code contributions, and contributions to community building. We will evaluate the contributions of these three aspects and encourage everyone to multi-dimensionally Participate in community building.
- Does BitSail support writing CDC data sources to Hudi?
Byte’s internal CDC data source is quite different from open source, so the internal CDC Connector is still in the stage of open source transformation. Our plan is to investigate and access some well-known open source CDC Connectors in November and December. At the same time, the development is completed and submitted to BitSail's warehouse.
- Is there a limit to the number of prizes in the incentive plan?
There is no limit to the number of prizes in the incentive plan, and we hope that everyone can participate widely.
- Can sub-database and sub-table be supported at present?
Currently it is not supported. I understand that the deeper level of this problem is that users are more concerned about whether a task can be imported into Hudi based on CDC data. This is also a feature that has received a lot of response from the community. We will advance with high quality after the development of CDC Connector is completed.
- Does the bottom layer of BitSail also flink ? What is the difference with the flink connector?
Currently we have some legacy connectors that are slightly coupled with flink. But our long-term development route is to decouple from the underlying engine. At present, the Reader and Writer interfaces of the new interface are decoupled from the engine. In the future, users will not feel the underlying engine during use.
- Does BitSail support sql, like flink?
At present, many users are more concerned about whether the intermediate support supports transform. Currently, an interface for transform is reserved, but there is no connection to the Sql engine. If you are interested, you can raise an issue on GitHub, and we will make an implementation after evaluation.
- Does BitSail support the scenario of one source and multiple targets? Like value conversion, one input, multiple output support etc.
There is a scene where multiple data sources are written to Hudi inside Byte, so the BitSail engine level supports it, but there are many scenarios with multiple inputs and multiple outputs, such as whether aggregation is required for multiple inputs, multiple Whether to simply copy data or split data when outputting. These issues need to be customized based on specific usage scenarios.
- Does BitSail support springboot3?
Not supported.
- CDC is synchronized to mq, and capacity expansion will cause disordered messages. How to solve this problem?
This problem is difficult. Improving the robustness and fault tolerance mechanism of the link can minimize the impact of short-term out-of-sequence. The solution we adopt is to reserve a time window when the binlog is archived offline to tolerate short-term out-of-sequence scenarios. The real-time scenario relies on the sorting mechanism of udi to ensure the final consistency. As long as the data on the link is not lost, the data falling into the lake or warehouse can guarantee the accuracy.
- Does BitSail support geometric types?
Not yet supported.
- How do incremental updates work?
There is a set of CDC mechanism in Byte, which sends all the full data and incremental data into the Message Queue, and the BitSail engine directly connects to the Message Queue to combine the full data and the incremental data.
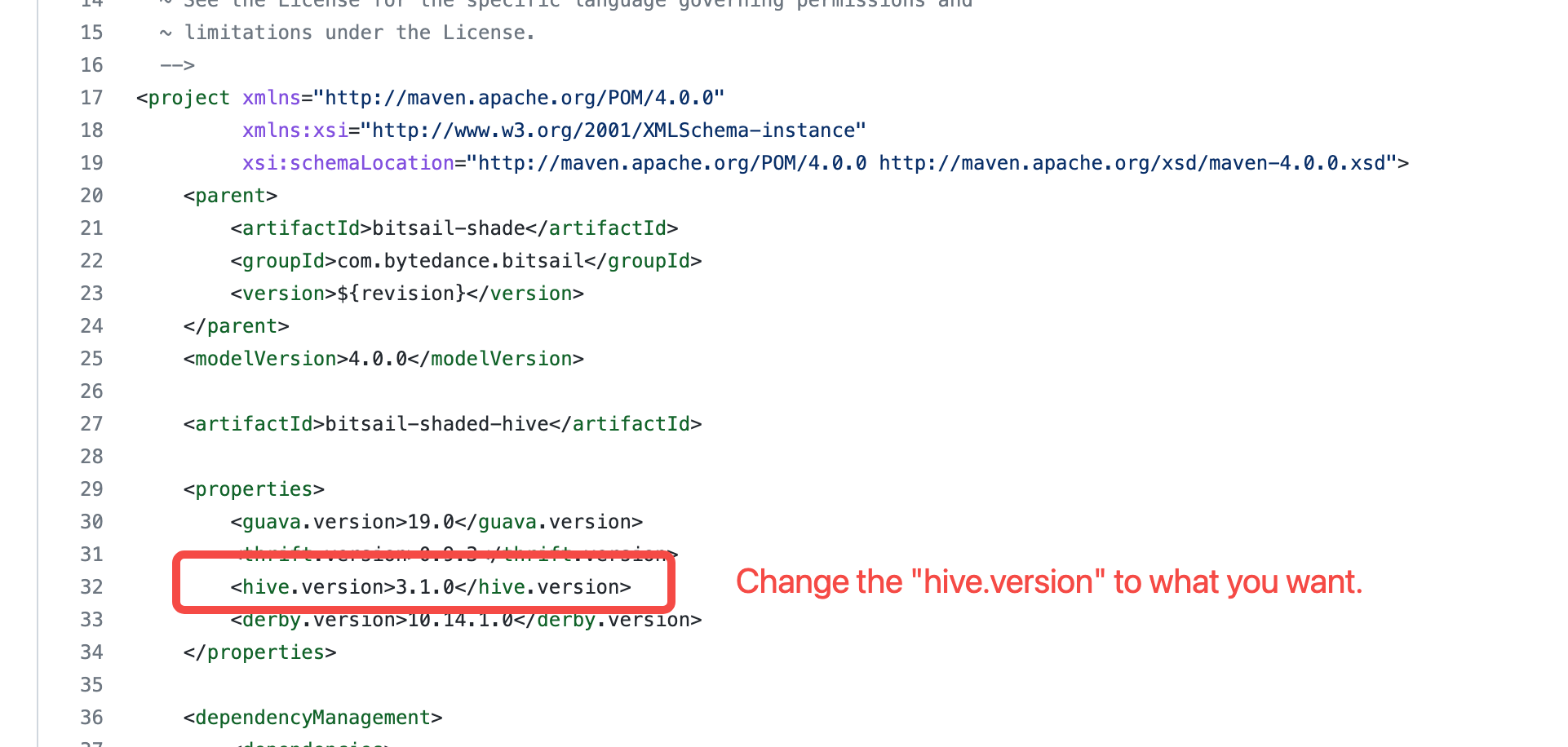
- How to deploy bitsail in hive2.x or hive3.x?
BitSail uses a shaded module, namely bitsail-shaded-hive, to import hive dependencies. By default, BitSail uses 3.1.0 as hive version. Therefore, if you want to deploy BitSail in different hive environment, you can modify the
hive.versionproperty in bitsail-shaded-hive.
- Does BitSail support JDK 11?
Currently, BitSail only support JDK 8.
- Tests failed when running integration tests or E2E tests locally?
BitSail uses docker to construct data sources for integration tests and E2E tests. Therefore, please make sure docker is installed before run these two kinds of tests.
If tests still failed after docker is installed, please open an issue for help.
- How to test hadoop related connector (e.g., hive) locally, if there is no hadoop environment?
After building BitSail project with build.sh script, all the libs and scripts are packaged into
outputfolder.To test hadoop related connector (e.g., hive) locally, please download the following two jars into
output/embedded/flink/lib.Then you can submit test job in
outputfolder.
- How to run E2E test on flink engine if your OS/ARCH is not linux/amd64 or linux/arm64?
Current flink executor for E2E test only supports linux/amd64 and linux/arm64.
If you want to run E2E test on flink engine, you need to build a flink image for your OS/ARCH. You can refer this document for detailed instructions: Support multi-arch flink docker image.
Then you can replace the docker image used in related Flink executor(s).